
Last time we converted audio buffers into images. This time we’ll take these images and train a neural network using deeplearn.js. The result is a browser-based demo that lets you speak a command (“yes” or “no”), and see the output of the classifier in real-time, like this:
Curious to play with it, see whether or not it recognizes yay or nay in addition to yes and no? Try it out live. You will quickly see that the performance is far from perfect. But that’s ok with me: this example is intended to be a reasonable starting point for doing all sorts of audio recognition on the web. Now, let’s dive into how this works.
Quick start: training and testing a command recognizer
Here’s how you can train your own yes/no classifier:
- Go to the model training page. It will take a bit of time to download the training data from the server.
- Click the train button, and you’ll see a graph showing training progress. Once you are ready (this will take a while, perhaps 500 iterations or 2 minutes, depending on your hardware), stop training, and press the save weights (file) button. This will download a JSON file.

- Then go to the inference demo page, press the load weights (file) button and select the downloaded JSON file to load the trained model.
- Flip the switch, grant access to the microphone and try saying “yes” or “no”. You’ll see microphone and confidence levels indicated at the bottom of the page.

The above is a mechanistic account of how the training example works. If you are interested in learning about the gory (and interesting) details, read on.
Data pre-processing and loading
Training a neural net requires a lot of training data. In practice, millions of examples may be required, but the dataset we’ll be using is small by modern standards, with just 65,000 labeled examples. Each example is a separate wav file, with the label in the filename.
Loading each training wav as a separate request turned out to be quite slow. The overhead from each request is small, but when compounded over a few thousand times, really starts to be felt. An easy optimization to load data more quickly is to put all examples with the same label into one long audio file. Decoding audio files is pretty fast, and so is splitting them into one second long buffers. A further optimization is to use a compressed audio format, such as mp3. scripts/preprocess.py will do this concatenation for you, producing this mesmerising result.
After we “rehydrate” our raw audio examples, we process buffers of raw data into features. We do this using the Audio Feature extractor I mentioned in the last post, which takes in raw audio, and produces a log-mel spectrogram. This is relatively slow, and accounts for most of the time spent loading the dataset.
Model training considerations
For the yes/no recognizer, we have only two commands that we care about: “yes”, and “no”. But we also want to detect the lack of any such utterances, as well as silence. We include a set of random utterances as the “other” category (none of which are yes or no). This example is also generated by the preprocessing script.
Since we’re dealing with real microphones, we never expect to hear pure silence. Instead, “silence” is some level of ambient noise compounded by crappy microphone quality. Luckily, the training data also includes background noise which we mix with our training examples at various volumes. We also generate a set of silence examples, which includes only the background audio. Once we’ve prepared our samples, we generate our final spectrograms as our input.
To generate these final spectrograms, we need to decide on buffer and hop length. A reasonable buffer length is 1024, and a hop length of 512. Since we are dealing with sample rate of 16000 Hz, it works out to a window duration of about 60ms, sampled every 30ms.
Once we have labeled spectrograms, we need to convert inputs and labels into deeplearn arrays. Label strings “yes”, “no”, “other”, and “silence” will be one-hot encoded as a Array1Ds of four integers, meaning that “yes” corresponds to [1, 0, 0, 0], and “no” to [0, 1, 0, 0]. Spectrograms from the feature extractor need to be converted into an Array3D, which can be fed as input for the model.
The model we are training consists of two convolution layers, and one fully connected layer. I took this architecture directly from the MNIST example of deeplearn.js, and hasn’t been customized for dealing with spectrograms at all. As a result, performance is a far cry from state of the art speech recognition. To see even more mis-classifications, try out MNIST for audio which recognizes spoken digits (eg. “zero” through “ten”). I am confident that we could do better by following this paper. A real-world speech recognizer might not use convolution at all, instead opting for an LSTM, which is better suited to process time-series data.
Lastly, we want to tell the machine learning framework how to train the model. In ML parlance, we need to set the hyperparameters, which includes setting the learning rate (how much to follow the gradient at each step) and batch size (how many examples to ingest at a time). And we’re off to the races:
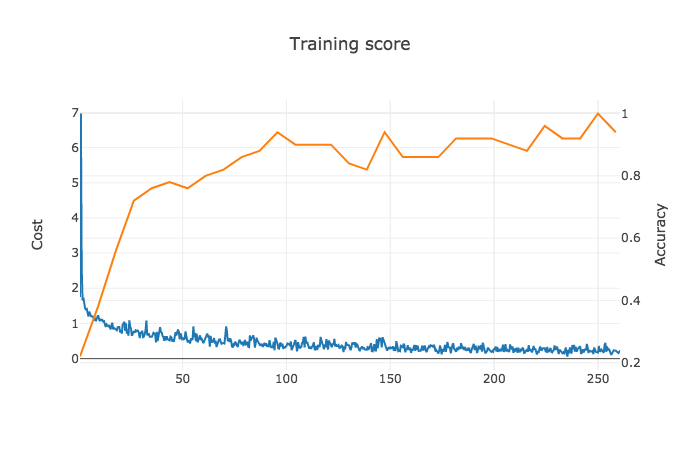
During training, the gradient descent algorithm tries to minimize cost, which you can see in blue. We also plot accuracy in orange, which is occasionally calculated by running inference on a test set. We use a random subset of the test set because inference takes time, and we’d like to train as quickly as possible.
Once we are happy with the test accuracy, we can save the model weights and use them to infer results.
Saving and loading model weights
A model is defined by its architecture and the weights of its weight-bearing nodes. Weights are the values that are learned during the process of model training, and not all nodes have weights. ReLUs and flatten nodes don’t. But convolution and fully connected nodes have both weights and biases. These weights are tensors of arbitrary shapes. To save and load models, we need to be able to save both graphs and their weights.
Saving & loading models is important for a few reasons:
- Model training takes time, so you might want to train a bit, save weights, take a break, and then resume from where you left off. This is called checkpointing.
- For inference, it’s useful to have a self-contained model that you can just load and run.
At the time of writing, deeplearn.js didn’t have facilities to serialize models and model weights. For this example, I’ve implemented a way to load and save weights, assuming that the model architecture itself is hard-coded. The GraphSaverLoader class can save & load from a local store (IndexedDB), or from a file. Ultimately, we will need a non-hacky way of saving and loading models and their corresponding weights, and I’m excited for the near future of improved ML developer ergonomics.
Wrapping up
Many thanks to Nikhil and Daniel for their hard work on deeplearn.js, and willingness to answer my barrages of stupid little questions. Also, toPete, who is responsible for creating and releasing the dataset I used in this post. And thank you dear reader, for reading this far.
I’m stoked to see how this kind of browser based audio recognition tech can be applied to exciting, educational ML projects like Teachable Machine. How cool would it be if you could make a self-improving system, which trains on every additional spoken utterance? The ability to train these kinds of models in the browser allows us to entertain such possibilities in a privacy preserving way, without sending anything to any server.
So there you have it! This has been an explanation of voice command recognition on the web. We covered feature extraction in the previous post, and this time, dug a little bit into model training and real-time inference entirely in the browser.
If you build on this example, please drop me a note on twitter.
Source:
This is a post by Boris Smus, originally from Boris’ website, posted to XRDS with permission of the author.