
In my previous post, I briefly mentioned that if the execution order of iterations in a loop can be altered without affecting the result, it is possible to parallelize the loop. In this post, we will take a look at why this is the case, i.e., how is execution order related to parallelism. Moreover, we will see how this idea can be further exploited to optimize code for data locality, i.e., how can reordering of loop iterations result in using the same data (temporally or spatially) as much as possible, in order to efficiently utilize the memory hierarchy.
On Execution Order of Loop Iterations
Let’s consider the examples I presented in the previous post. Following is the source code for the first example (implemented in Matlab).
for i = 1:size(A,2)
B(i) = A(i) * alpha;
end
The code consists of two equal sized row-vectors A and B, and a scalar alpha. The loop iterates over elements of A, multiplies each of these elements with alpha, and assigns the result to the corresponding element in B. Now let’s assume that both A and B have only 5 elements each. Then, we get the following by unrolling the loop.
B(1) = A(1) * alpha;
B(2) = A(2) * alpha;
B(3) = A(3) * alpha;
B(4) = A(4) * alpha;
B(5) = A(5) * alpha;
In the serial program listed above, there is a strict execution order imposed on the expressions above. That is, the expressions are evaluated in the ascending order of the value of the index variable i. However, a closer examination reveals that this execution order is not necessary to produce the correct result. The expressions above can be executed in any order, since each expression reads from, and writes to locations different from all other iterations. In the case of this particular example, all permutations of the above depicted order are valid. As an example, the following execution order will reveal same result as the above listing.
B(3) = A(3) * alpha;
B(5) = A(5) * alpha;
B(2) = A(2) * alpha;
B(1) = A(1) * alpha;
B(4) = A(4) * alpha;
Now let’s take a look at the second example. Here’s the Matlab code.
for i = 2:size(A,2)
B(i) = B(i-1) * A(i);
end
Unrolling the loop with 4 iterations gives us the following listing.
B(2) = B(1) * A(1);
B(3) = B(2) * A(2);
B(4) = B(3) * A(3);
B(5) = B(4) * A(4);
Again, the serial code imposes an execution order. In this case however, the imposed order is a necessary constraint that ensures the correctness of the result. Each expression writes to a memory location, which is read by the following expression. Another way to put it is that each expression in the listing above is dependent on the result generated by the previous expression. Therefore, in this case, there is only one execution order that guarantees correctness; none of the other permutations of this order preserve correctness.
So what is the message here? Well, in order for there to exist more than just the one execution order imposed by the serial code, dependences must not exist between the iterations of a loop.
Three types of dependences can exist between loop iterations. These are:
- Flow dependence: A flow dependence occurs if a statement
S1writes to a variable that is read by another statementS2. In the second example, there is a flow dependence between each pair of subsequent loop iterations. - Anti-dependence: An anti-dependence occurs if a statement
S1reads from a variable, which another statementS2overwrites subsequently. - Output dependence: An output dependence occurs if a statement
S1writes to a variable, which another statementS2overwrites subsequently.
If two loop iterations read from the same variable, there is no dependence, since read operations do not have side effects. However, if two iterations share a variable to which one or both iterations write, there is a constraint on the execution order. If this constraint is violated by reordering the iterations, the program’s correctness is not preserved, which may result in incorrect behavior. A compiler must always preserve correctness when applying optimizations, and therefore must preserve the execution order in the presence of dependences.
Note: These three types of dependences correspond to Bernstein’s conditions for parallelism, which were introduced in the paper available here. Moreover, the same concept is used in the design of microprocessor instruction pipelines, where flow dependence is called Read After Write (RAW) hazard, anti-dependence is called Write After Read (WAR) hazard, and output dependence is called Write after Write (WAW) hazard.
Parallelization and Flexibility in Execution Ordering
So, what does execution order have to do with parallelization? The answer is rather simple: If there are no dependences between two loop iterations, it does not matter which one is executed first. More significantly, it is possible to execute two such iterations at the same time, i.e., in parallel, since they do not affect each other in any way. Then, in principle, each individual iteration (or a group of iterations) can be assigned to a different processing unit for execution. Therefore, in order to find parallelism in a loop nest, a compiler must find flexibility in the execution order of the loop iterations.
Execution Order and Data Locality
The interesting thing is that the lack of dependences not only exposes parallelism, it also exposes opportunities for exploiting data locality. Before we discuss how, let’s take a look at the hierarchical organization of memory in a typical processor. This is depicted, below, in the following figure.
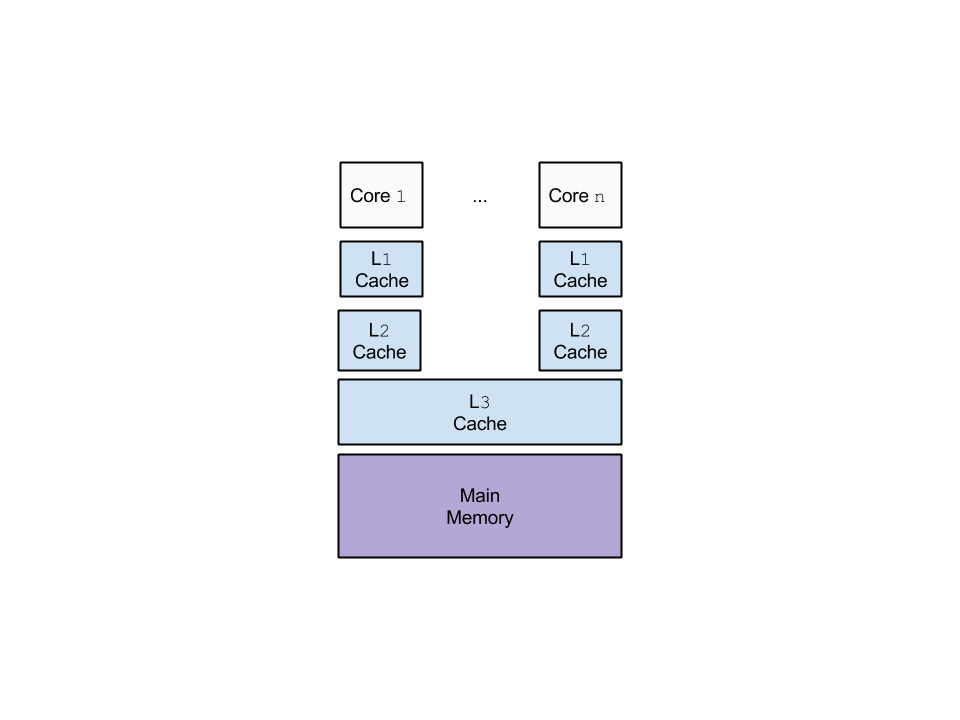
For a processor, fetching data from memory is a lot slower than performing arithmetic and logic operations. Moreover, the farther away in the memory hierarchy the data is located, the slower is the fetch operation. For instance, accessing data available in the processor’s registers (not depicted in the figure above) is very fast, almost as fast as performing an arithmetic operation. However, accessing data available only in the main memory can be more than a hundred times slower. There are very few registers available in the processor, which makes it impossible for most programs to keep all the required data in registers. Therefore, an optimized program tries to keep data in cache for as long as possible, so as to minimize the frequency of fetch operations directed toward the main memory. (Note: Even though there is a different value of latency associated with each level of cache, for simplicity, we will assume that there is one unified cache for which we will optimize our code)
Then, if a compiler can reorder loop iterations (or parts of the program) in such a way that the resulting code is optimized for efficient cache utilization, it can generate faster code. The basic principle here is the same as for parallelization: the possibility to alter execution order while preserving program correctness. This, as mentioned earlier, is only possible in the absence of dependences. Therefore, dependence analysis is not only useful for auto-parallelization, it is also used to generate programs that can efficiently utilize the memory hierarchy.
Let us consider the following example.
for i = 1:n
C(i) = A(i) - B(i);
end
for i = 1:n
C(i) = C(i) * C(i);
end
The listing above represents code for computing squares of differences between vector A and vector B. The first loop computes element-wise differences between A and B, and the second loop computes element-wise squares for the result vector C. For this code, the result value needs to be written twice to the memory location C(i). Moreover, if size of vector C is larger than the cache size, it will have to be fetched again from the memory after the first loop (so that it can be used in the second loop). Can we do better?
Now consider the following code that generates the same result.
for i = 1:n
C(i) = A(i) - B(i);
C(i) = C(i) * C(i);
end
This code is an example of loop fusion, i.e., the two loops have been fused into one loop. Loop fusion is possible here because each iteration of the second loop is dependent only on the corresponding iteration of the first loop; loop fusion does not violate any dependences, and therefore results in a correct program transformation. Now, within each iteration, the difference — C(i) — can be stored in a register, which can then be used to compute the square. Also, the result is written only once to C(i). This improved memory access behavior results in faster code.
Up Next
We saw in this post that in order for a compiler to determine whether or not a loop nest can be parallelized, it must analyze dependences between loop iterations. But how does a compiler determine whether or not dependences exist? We will start developing the answer to this question in the next post, by modeling the question as a problem in Linear Algebra and Integer Linear Programming.