
Processing large datasets or working with huge data is a usual stage in almost any kind of research. The problem appears when processing these data requires long processing time on any kind of personal laptop. In order to solve that issue, we have at our hands the possibility of using any major compute cloud provider in order to accelerate that processing stage wasting minimal time and resources. Cloud computing allows us with a few clicks to build a computer cluster, process our data, get the results and destroy that cluster for only a few dollars.
The way cloud computing improve our research is both qualitative and quantitative: multiple analysis could be done at the same time with a significant time processing reduction. The more analysis done, the best and complete our result will be.
Time in an important variable in any research. Sometimes complementary research cannot be done due to timing problems. Cloud computing in that way improves the quality of our research allowing complementary research being done.
In order to start working with cloud computing, a lot of providers are available but I want only to comment my experience with the major providers: Amazon Aws, Google cloud and Microsoft Azure.
In order to test the services, these 3 providers allow the user to run their services for a limited time for free.
Others providers may offer the creation of virtual machines (or computer instances). Computer instances are basically a computer, where you can install any software and run your analysis. This is more complex than directly use a designed application for the target service as the major providers have.
Basic problem
The basic problem to solve with the help of the cloud computing is the ‘Map-Reduce’ problem. On this problem, the researcher has a large dataset. This dataset has to be processed because the result will only be part of this data aggregated by a key or keys. So the ‘Map’ stage split the data into little chunks to be processed on single nodes (or computer instances) and the ‘Reduce’ stage performs the aggregation resulting in a complete new computed dataset.
Map-Reduce was first introduced by Google in 2004 and has a US patent # 7650331 on “System and method for efficient large-scale data processing”. The main benefit of the Map-Reduce framework is its fault-tolerance achieved by its architecture.

MapReduce
The basic configuration a Map-Reduce problem can be done in any computer, not only on cloud providers. The benefits for us is the quick start and the fewer configuration problems we will have. The less time you spent processing data the more time you have for the data analysis and getting conclusions.
The basics include using the Apache Hadoop or Apache Spark solutions. Other software solutions can be used but these two are open source, free to use and are widely the most used solutions for map reduce tasks.
Amazon AWS has a service called Elastic Map Reduce. This is basically a Hadoop (or other services like Spark or Presto) installation. You may select the type of installation, the number of computers (instances) in the cluster and the configuration of each instance (CPU, mem, HDD)… After the selection of the hardware and software, you only have to select the source folder for the data (only in the Amazon S3 service) and AWS will do the rest. Only wait for the results with a great cup of coffee.

EMR AWS console

EMR AWS flow
On Google Cloud, you will find something similar: Google Cloud Dataproc. Out of the box Apache Spark, Apache Hadoop and other software solutions related to data processing. The job processing is a two step procedure: first create the cluster and then submit the MapReduce functions. Once this is done, wait for the results.

Create cluster Google Cloud

Cluster config Google Cloud
And finally, Microsoft Azure presents HDInsight, a complete Hadoop solution. The process for creating a job, like the other 2 providers is very similar. First, create the cluster and then submit your job and wait for the results.

Custer config Azure
What is common on this 3 cloud providers is that the “Map” and the “Reduce” stage must be done by a piece of software developed by the researcher. Hadoop works best with Java so pack your piece of code in a ‘jar’ file and keep it ready to upload it to the Hadoop job. The Hadoop master will send the appropriate piece of code and piece of data to the Hadoop workers and will get the results from these workers in order to process the final results.
Sample Job
The common sample job is the ‘word’ count. A sample for the Microsoft Azure service can be found here and a sample from the Apache Hadoop wiki here.

Word Count Hadoop
On Amazon AWS the result of executing a job will be like:
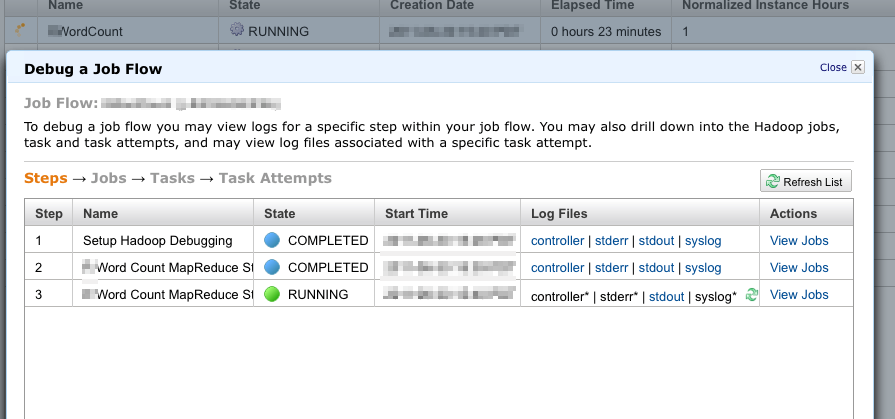
AWS Job List
Sample data sets for download
Data samples for your research or learning how Hadoop works can be downloaded from: