
Bisection or Binary logic is an example of a simple yet powerful idea in computer science that has today become an integral part of every computer scientist’s arsenal. It stands synonymous to logarithmic time complexity that is no less than music to a programmer’s ears. Yet, the technique never fails to surprise us with all the creative ways it has been put to use to solve some tricky programming problems. This blog-post will endeavour to acquaint you with a few such problems and their solutions to delight you and make you appreciate it’s ingenuity and efficacy.
I’d like to thank Janin Koch for her help and efforts.
The blog-post has the following flow of events:
|
You can choose to skip the ‘Applications to Diverse Programming Problems’ section to directly read the problems without having to go through the preliminary discussion on the basics of the technique.
Prerequisites
I assume that the reader is familiar with Big-Oh notation used for describing the time complexity requirements of programs. For running and understanding the code, the reader must be familiar with programming in Python.
I. Defining the Logic
Let’s begin by first describing what the technique stands for and why do we use it? Consider an imaginary game with a small number of paper cups of varying heights, presented to you. Each cup has a sticker on it that tells the exact height of the cup. The sticker is however hidden from you. The cups are arranged in front of you in the order of increasing height (as depicted in Fig. 1).

Fig. 1: A visual depiction of the paper cup game.
At a time, only a single cup can be picked and the value printed on it’s sticker can be noted. Suppose you’re asked to locate a cup having a particular height. How will you accomplish the task? (without using a measuring scale of course!)
You’ll probably begin by intuitively picking up a cup whose height you guess to be the same as the one you’re looking for. If it isn’t the case, you’ll then likely select the cup next in line to either to the left or to the right depending upon whether the selected cup’s height overshot or fell short of the target height. You might end up repeating the last step some more times till you find the cup with the correct height.

Fig. 2: Paper cup example – the approach to locate the cup of target size (25cm).
What is useful about the above approach? The fact that the cups are ordered by increasing height helps eliminate a portion of the cup sequence that would otherwise have to be considered, making the search space smaller (as depicted in Fig. 2).
Let us now modify the game to make it more challenging – let all the cups be of the same height, with the labels representing arbitrary integers. The cups are arranged in the order of non-decreasing (described in Fig. 3) label values.
Fig. 3: A non-decreasing sequence of integers refers to a sequence similar to the ones depicted above.
With no obvious cue available to us such as the heights of the cups, the task now is to find a particular target label among the cups. What should our approach be? The most basic or naive approach, referred to as Linear Search, is to start picking-up cups one at a time from one end and search for the target label. If the number of cups is small (as assumed initially), it is a feasible approach. However, if it isn’t the case, then checking every cup against the target label may no longer be a feasible proposition. The amount of time to locate the desired cup will be proportional to the number of cups present, which can be a large number thus making our exercise timewise expensive.
Let’s add another constraint to the target here – how will you find a particular label value in the least number of steps possible?
Can we do better than Linear search? And if so, what feature of the problem can we make use of to help realize the goal?
Upon pondering over it, you may observe that the cup labels are in a non-decreasing order. What does that convey to us? Simply, that the facet, which we had earlier identified as part of the initial technique i.e. elimination of cups to next consider, is still applicable. Yet how it is utilized here, is different. Think of a way to ascertain which direction (left or right) we must proceed to locate the cup with target label. We might pick any cup up, note the label and make the choice. Out of the remaining cups to consider, how will we proceed? By repeating the same step i.e. randomly choose a cup, check if it’s the desired one, if not, compare label value to ascertain in which direction to apply the step again next. Yet we ought to remember the search has to be conducted in the least number of steps. This isn’t addressed by the random choice at the beginning of the step. What can we do to regulate the behaviour? Select an element at a particular place in the sequence with the best choice being the middle-most element.
The strategy above halves the input space each time we conduct the step. It is thus called the Bisection Search or Binary Search (Illustrated in Fig. 4). Like any search strategy, we can make it return an integer value, typically -1, to indicate the absence of the target from the given sequence. Note that it is a prerequisite that the input sequence must be sorted for the Bisection Search to be applicable. The order of sort can either be non-increasing or non-decreasing.
Binary Search represents an algorithm belonging to the paradigm of Divide-&-Conquer (D&C) algorithms that operate by dividing the input space into distinct, smaller spaces (referred to as the ‘Divide’ step) and repeating the process till the sub-problems obtained are small enough to be solved directly (referred to as the ‘Conquer’ step). Binary Search however does not strictly adhere to the structure of a typical D&C algorithm as it does away with the ‘Combine’ step that is responsible for combining the solutions to the sub-problems to obtain solutions to the original problem.
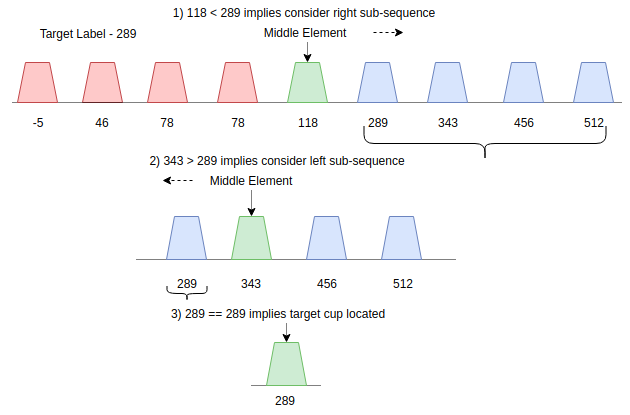 Fig. 4: A sample step-wise execution of Bisection Search to locate the correct target label.
Fig. 4: A sample step-wise execution of Bisection Search to locate the correct target label.
Python code for Bisection Search:
# Author - Abhineet Saxena
def bis_search(iseq, xkey, lidx, ridx):
"""
A Recursive method that performs Bisection Search over the supplied array.
:param iseq: a sorted, non-decreasing sequence of integers.
:param xkey: The target value to be searched for in the given sequence
:param lidx: left index marking the left-most edge of the sub-sequence under consideration.
:param ridx: right index marking the right-most edge of the sub-sequence under consideration.
:return: A non-negative integer specifying the location of the target value.
"""
if lidx <= ridx:
mid_idx = lidx + (ridx - lidx)//2 # Calculation of the middle index
mid_val = iseq[mid_idx]
if mid_val == xkey:
return mid_idx
elif mid_val < xkey:
return bis_search(iseq, xkey, mid_idx + 1, ridx)
else:
return bis_search(iseq, xkey, lidx, mid_idx - 1)
else:
return -1
print("Specify a sorted integral sequence (non-decreasing):\n")
# The input must be of the form “x y z ...” where the alphabets x,y,z
# etc. represent separate integers.
# Example sequence “-99 -3 0 2 7 10 12 56 64 89”
ip_arr = [int(elem) for elem in input().split(' ')]
len_arr = len(ip_arr)
print(bis_search(ip_arr, 78, 0, len_arr - 1))
A peculiarity can be observed in the code above in the middle index calculation step. The statement is equivalent to ‘floor( (lidx + ridx)/2 )’ yet the specified way above takes care of addition overflows that occur when i) the number of elements in the array is very large (a billion or more) and ii) the sum of lidx and ridx exceeds the maximum positive integral value that can be represented by the programming language.
II. Applications to Programming Problems
Now that we’ve covered the basic algorithm, let’s take up the programming problems one by one:
[Before commencing however, I’d like for the reader to try and think of a possible solution approach for each of the presented problems without immediately referring to the solution descriptions provided – even if it means writing messy pseudocode for the approach on a piece of paper. It won’t be much of a challenge if you never give it a try.]
1)
Problem statement:
In a sorted array ‘A’ of distinct elements, find the index of an element such that A[idx] = idx.
Description:
As an example, consider a sequence such as the one depicted below:

We can observe that at the 8th index of the array, the value of the element is 8, i.e. A[8] = 8. How to locate such an element programmatically in the best possible way?
Solution Approach:
The most naive approach one can think of is to test every element of the array for equality with its index. But we can observe that for a large number of elements, the approach becomes infeasible. It’s complexity is O(N) in the worst case for an N element input array.
For a better approach, we need to observe a pattern that associates the indices with the stored values. In the example array above, we can see that for every index value less than 8, the value stored in A at that index is less than the index value. Eg.(value stored at idx < idx) -15 < 3; -3 < 4; 0 < 5; 2 < 6 and 5 < 7. Also, for every index value greater than 8, value stored at the index is greater than the index (27 > 9; 54 > 10).
Now how can we utilize the above-found observation to arrive at the solution? Since the behaviour of the relation linking the array indices with their stored values changes at the location of the desired index, we can modify our binary search procedure to then use this change in order to seek towards the desired index location.
# Author - Abhineet Saxena def mod_bsrch(iseq, lidx, ridx): """ A Recursive method that performs Modified Bisection Search to locate the element such that iseq[idx] == idx. """ if lidx <= ridx: # Calculation of the middle element mid_idx = lidx + (ridx - lidx)//2 mid_val = iseq[mid_idx] # Checks for the presence of the desired element if mid_val == mid_idx: return mid_idx elif mid_val < mid_idx: # We're to the left of the target element -> move right return mod_bsrch(iseq, mid_idx + 1, ridx) else: # We're to the right of the target element -> move left return mod_bsrch(iseq, lidx, mid_idx - 1) else: return -1 print("Specify a sorted integral sequence (non-decreasing):\n") ip_arr = [int(elem) for elem in input().split(' ')] len_arr = len(ip_arr) print(mod_bsrch(ip_arr, 0, len_arr - 1))
The complexity of the above solution approach is O(logN) for any worst-case input of size N.
2)
Problem Statement:
In an unsorted sequence of integers, find the position of the end of the integer array when the rest of array is populated with some symbol (eg. $) which is known to us such that (a) the end of the array isn’t known and (b), the problem variant, where the size of array is not specified.
Description:
In the first problem (a), the size of the array is provided to us. A sample array looks like the following:
 Here, the index 4 is the correct answer as it refers to the array index where the last integer element can be found. All elements beyond it are marked by dollar symbol. A possible input can be an array that only comprises of dollar symbols. How does our search find the desired index or report if none can be found?
Here, the index 4 is the correct answer as it refers to the array index where the last integer element can be found. All elements beyond it are marked by dollar symbol. A possible input can be an array that only comprises of dollar symbols. How does our search find the desired index or report if none can be found?
For the problem variant (b), the size of the array isn’t available to us. The end of the array has been demarcated by a continuous, indefinite sequence of some symbol e.g. ‘#’. A sample input array may appear as follows:

For the above array, the correct answer is 4.
Solution:
(a)
To perform better than linear search, we again need to identify a pattern that can make our bisection search feasible to apply. Although it may seem contradictory but bisection search is applicable here. The caveat being that we aren’t searching for a particular integer element. Instead, we’re trying to locate the end of the integer array.
The decision event for our search is firstly if the concerned element is an integer or not. If the element is an integer such that it’s subsequent element is the ‘$’ symbol, we’ve found the desired index value. If the subsequent element is not the ‘$’ symbol, the search then proceeds towards the right subsequence.
If the concerned element is the $ symbol, we first check if the prior element is an integral value. If it is so, we return the index of the element. If it is a dollar symbol, we then consider the left sub-sequence.
# Author - Abhineet Saxena
def mod_bsrch_p2a(iseq, slen, lidx, ridx):
"""
A Recursive method that performs Modified Bisection Search to locate
the end of integer array over the specified input.
"""
if lidx <= ridx:
# Calculation of middle index
mid_idx = lidx + (ridx - lidx)//2
mid_val = iseq[mid_idx]
if mid_val != '$':
if mid_idx != slen - 1:
if iseq[mid_idx + 1] == '$':
return mid_idx
if iseq[mid_idx + 1] != '$':
return mod_bsrch_p2a(iseq, slen, mid_idx + 1, ridx)
else:
return mid_idx
elif mid_val == '$':
if mid_idx != 0:
if iseq[mid_idx - 1] != '$':
return mid_idx - 1
else:
return mod_bsrch_p2a(iseq, slen, lidx, mid_idx - 1)
else:
return -1
else:
return -1
print("Specify the test input sequence:\n")
# Sample inputs:
# (#1) -1 0 7 8 65 23 $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $
# (#2) $ $ $ $ $ $ $ $ $ $
# (#3) 1 56 78 0 -3 5 -9 45
# List comprehension to process the input
ip_arr = [int(elem) if elem != '$' else elem for elem in input().split(' ')]
# Store the array length
len_arr = len(ip_arr)
# Make the function call
print(mod_bsrch_p2a(ip_arr, len_arr, 0, len_arr - 1))
(b)
Here, we’re confronted with the problem of not knowing the size or bound of the array at the beginning. Our procedure requires the right index to mark the end of the sequence under consideration. What can we do in such a case? Firstly, we become aware of the need to delimit our search space in order for Bisection Search to be applicable. How can it be effected? Here, we use an idea called ‘Unbounded’ or ‘Exponential’ bisection search. We first explore the input space by skipping elements with incremental powers of two to reach a point where the value at the current index exceeds the target value, or in our case, crosses the boundary of the integer array. We then apply Bisection Search over this reduced search space to find the desired index.
 Fig. 5: The search proceeds by exponentially moving from the indicated indices till it lands up on the 8th index whereby the while loop concludes. The lidx, ridx are supplied as indices marking the sub-array that is further evaluated using the ‘bsrch_proc()’ method.
Fig. 5: The search proceeds by exponentially moving from the indicated indices till it lands up on the 8th index whereby the while loop concludes. The lidx, ridx are supplied as indices marking the sub-array that is further evaluated using the ‘bsrch_proc()’ method.
# Author - Abhineet Saxena
def bsrch_proc(iseq, lidx, ridx):
if lidx <= ridx:
mid_idx = lidx + (ridx - lidx) // 2 # Calculation of the middle index
mid_val = iseq[mid_idx]
if mid_val != '$' and mid_val != '#':
tval = iseq[mid_idx + 1]
if tval == '$' or tval == '#':
return mid_idx
else:
return bsrch_proc(iseq, mid_idx + 1, ridx)
else:
return bsrch_proc(iseq, lidx, mid_idx - 1)
else:
return -1
def mod_bsrch_p2b(iseq):
"""
A Recursive method that performs Exponential Bisection Search to locate the end of integer array
over the specified input.
"""
lidx, ridx, cidx = [0]*3
tidx = 0
cval = iseq[tidx]
while True:
# If considered element is an integer
if cval != '$' and cval != '#':
# If subsequent elem. not an integer
if iseq[tidx + 1] == '$' or iseq[tidx + 1] == '#':
return tidx
else:
# Traverse input array by moving at indices at position 2^i where i is inc.’t at each iteration
tidx = 2 ** cidx
cval = iseq[tidx]
lidx = ridx
ridx = tidx
cidx += 1
else:
break
if ridx == 0:
return -1
else:
return bsrch_proc(iseq, lidx, ridx)
print("Specify the test input sequence:\n")
# Sample inputs:
# (#1) -1 0 7 8 65 23 $ $ $ $ # # # # # # # # # # # # # # # # # # # # #
# (#2) $ $ $ $ $ $ $ $ $ $ # # # # # # # # # # # # # # # # # # # # #
# (#3) 1 56 78 0 -3 5 -9 45 # # # # # # # # # # # # # # # # # # # # #
# A list comprehension to process input
ip_arr = [int(elem) if (elem != '$' and elem != '#') else elem for elem in input().split(' ')]
# Store the array length
len_arr = len(ip_arr)
# Make the function call
print(mod_bsrch_p2b(ip_arr))The complexity of both the solutions above remains O(logN). The solution for problem (b) has the same complexity as that of (a). It is so due to the logarithmic nature of the initial ‘exploration’ process followed by a smaller, logarithmic cost incurred over the smaller sub-sequence that is finally searched for the target index.
3)
Problem Statement:
The Peak finding problem.
Description:
A ‘peak’ element in a given array is an element which is no less than its neighbours. As an example, consider the below given array.
 If we plot the array elements on a graph, we’ll obtain the following:
If we plot the array elements on a graph, we’ll obtain the following:
 We can clearly observe there are two peak elements above, namely 25 and 37.
We can clearly observe there are two peak elements above, namely 25 and 37.
Also, for a given sequence such as {25, 10, 6} or {7, 18, 37}, the respective peak elements 25 and 37 are corner elements. If a sequence such as {12, 12, 12} is considered, then any of the elements is a peak.
Let us however, consider a more strict definition for a peak element.
Constraint [C1] – Let it be defined as one that is greater than its neighbours. In such a case, for the last sequence that we observed, there won’t be any peak elements. Similarly, for a sequence such as {6, 25, 25, 13}, there won’t be any peak elements possible.
Constraint [C2] – We also assume that the given input sequence only consists of distinct elements.
The task at hand is thus to write a program that can locate any such element (satisfying C1) given an array ( satisfying C2) or convey the absence of such an element if none is present.
Solution:
Although C1 makes the problem appear to be a tough nut to crack, yet C2 works in our favour. If the input consists of distinct elements, the presence of a peak element is guaranteed (think about it – out of any given ‘n’ distinct elements, won’t the largest one definitely be a peak?). Since, like always, we’re looking to perform (asymptotically) better than a linear scan of the sequence, we need to identify some characteristic of the problem that can then be leveraged to possibly apply the Bisection Logic.
Consider an input sequence such that we sample the middle element which is not a peak. Since all elements are distinct, it can’t be be equal to any of the neighbours. It is thus lesser in value as compared to one or both of its neighbours. Thus if we next choose a sub-array with a neighbour greater in value, only two cases can occur – either all elements are arranged monotonically (in strict increasing or decreasing order), or not (i.e. an unsorted sequence of elements is present) in the subsequence. In the former case, the corner element of the subsequence will be a peak whereas in the latter case, presence of a peak element is guaranteed (an element greater than the mid element is present in subarray – its other neighbour can either be greater in value or less than it. In either case, we’ll be able to locate a peak).
Thus the condition to evaluate in the procedure will be to test the element under consideration if its peak or not. The outcome will determine the choice of subarray we’ll next evaluate. Since we’ll always choose the subarray with a larger neighbour with respect to the mid, we’ll eventually converge at an element which will be a peak.
# Author - Abhineet Saxena
def mod_bsrch_p3(iseq, slen, lidx, ridx):
"""
A recursive impl. of modified Bisection Search to find a peak element in the given array.
"""
if ridx - lidx <= 1: if ridx - lidx == 0 or iseq[lidx] > iseq[ridx]:
return iseq[lidx]
else:
return iseq[ridx]
else:
midx = lidx + (ridx - lidx)//2
midval = iseq[midx]
if midval > iseq[midx - 1]:
if midval > iseq[midx + 1]:
return midval
else:
return mod_bsrch_p3(iseq, slen, midx + 1, ridx)
else:
return mod_bsrch_p3(iseq, slen, lidx, midx - 1)
print("Specify an input integral sequence:\n")
"""
Sample input sequences -
(#1) 6 15 25 19 10 22 37 31 24 16
(#2) 2 13 26 37 45 58 69 75
(#3) 1 76 18 -3 24 28 37 36 20 11
"""
ip_arr = [int(elem) for elem in input().split(' ')]
len_arr = len(ip_arr)
print(mod_bsrch_p3(ip_arr, len_arr, 0, len_arr - 1))
The above solution can be tweaked to solve the peak finding problem for the relaxed definition of the peak element.
An interesting problem is to locate the peak (C1) in a given array where constraint C2 isn’t present. Here, bisection search based implementation is no longer applicable because ascertaining the absence of a peak element will require complete traversal of the array.
4)
Problem Statement:
Finding frequency of elements in a sorted array with duplicates in less than O(n) time.
Description:
Note – Constraint [D]: If the number of distinct elements is equal to some constant ‘c’, only then will an approach with the desired complexity be feasible.
Otherwise, a Linear Scan based approach will be appropriate.
For example, consider a sequence such as {1, 1, 6, 7, 7, 7, 7, 7, 7, 11, 11, 11, 11, 11, 11, 11, 12, 12, 12, 12, 12}. Here, the number of distinct elements is 5. It is referred to as a constant here as it is not functionally dependent on the total number of elements N in the input array i.e., c != <not equal> f(N) where f is some function. If however, every element is distinct, then c == N which means it is no longer a constant.
The approach feasibility is better understood in an asymptotic sense. For very large sized inputs ( N > 100,000), a marked difference in performance will be observed with the technique that you formulate subject to the input array satisfying [D].
The task is thus to output the frequency of all the elements present in the given array.
Solution:
Let’s try and identify any observable pattern that can be leveraged to apply bisection search. Consider the following example:
{1, 1, 1, 1 ,1, 7, 7, 7, 7, 7, 10, 10, 10, 10, 10, 10, 10, 24, 24, 24, 24, 24, 24, 24, 24}
We have continuous runs of elements here as the input array is sorted. The length of each run is therefore equal to the difference b/w the indices on the first and last element of the run. But how to ascertain the right end index of each run? For the purpose, recall how we applied the exponential Binary Search concept to explore a sequence whose end wasn’t known. We’ll use the same concept here to find the ending index of each run. Thereafter a Python dictionary will be used to store the frequency values for all the distinct elements.
# Author - Abhineet Saxena
def bsrch_util(iseq, xkey, slen, lidx, ridx):
midx = lidx + (ridx - lidx)//2
midval = iseq[midx]
if midval == xkey:
if midx != slen - 1:
if iseq[midx + 1] != xkey:
return midx
else:
return bsrch_util(iseq, xkey, slen, midx + 1, ridx)
else:
return slen - 1
else:
if midx != 0:
if iseq[midx - 1] == xkey:
return midx - 1
else:
return bsrch_util(iseq, xkey, slen, lidx, midx - 1)
else:
return 0
def mod_bsrch_p4(iseq, slen):
“””
A modified exponential Bisection search impl. that calculates the frequency of all the elements in the array.
“””
elemc = iseq[0]
iterv, delta = 0, 0
fidx1, fidx2 = 0, 0
freq_dict = {}
while fidx2 < slen - 1:
fvar = 0
iterv, lidx, ridx, tidx = [0] * 4
# Performs exponential Bisection search
while fvar == 0 and tidx + delta < slen:
if iseq[tidx + delta] == elemc:
tidx = 2 ** iterv
iterv += 1
lidx = ridx
ridx = tidx + delta
else:
fvar = 1
# For single elements, the frequency is recorded differently, bypassing the call to utility function
if iterv == 1:
freq_dict[elemc] = 1
fidx1, fidx2, delta = [ridx] * 3
if fidx2 < slen - 1:
elemc = iseq[fidx2]
else:
freq_dict[iseq[slen - 1]] = 1
continue
# Call to Utility function for finding the right end of the run of element duplicates
if tidx + delta <= slen - 1:
fidx2 = bsrch_util(iseq, elemc, slen, lidx, ridx)
else:
fidx2 = bsrch_util(iseq, elemc, slen, lidx, slen - 1)
# Setting the frequency counts correctly after locating the end of duplicate element run
if fidx2 != slen - 1:
delta = fidx2 + 1
if fidx1 == 0:
freq_dict.setdefault(elemc, fidx2 - fidx1 + 1)
else:
freq_dict.setdefault(elemc, fidx2 - fidx1 + 1)
elemc = iseq[delta]
fidx1 = delta
else:
freq_dict.setdefault(elemc, fidx2 - fidx1 + 1)
return freq_dict
print("Specify the test input sequence:\n")
"""
Sample Inputs -
(#1) - 1 2 2 3 3 3
(#2) - 4 4 4 7 7 7 7 7 9 9 9 9 9 9 11 11 11 11 11 11
(#3) - 1 1 1 1 1 1 7 7 7 7 7 7 7 7 7 10 10 10 10 10 10 10 10 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24
(#4) - 1 1 1 3 4 4 4
(#5) - 1 1 1 2 2 2 2 2 2 3 4 4 4 5 6 6 6 6 6 6 6 6 6 6 6 6 7 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 9 10 10
(#6) - 1 2 3 4 5 6 7 8 9
(#7) - 1 1 1 1 1 1 1 2
"""
ip_arr = [int(elem) for elem in input().split(' ')] # A list comprehension to process input
len_arr = len(ip_arr) # Store the array length
print(mod_bsrch_p4(ip_arr, len_arr)) # Make the function call
The above solution has a logarithmic time complexity as O(c*logN) with ‘c’ as defined previously. The upper bound presented isn’t tight, yet for the purpose of describing the asymptotic behaviour of the method above, it should suffice. Note we require ‘c’ to be a constant else the complexity no longer remains logarithmic.
Conclusion
We experienced the versatility of Bisection Search in solving some distinct problems and realized the need to think creatively when it comes to solving programming problems (Programming, afterall, is an art form, as stated by Donald Knuth himself in his seminal books carrying a similar name). Yet the above covers only a portion of what’s possible with this technique. You can refer to [1] for more examples of how the technique has been applied to solve problems with [2] presenting even more challenges for you to contemplate over. A great utilization of the technique is offered by the Bisection Section for calculating roots of equations. You can learn more about it at [3]. Some variations over the technique can be tried out at [4] to gauge their workings and efficacy. A discussion on the time complexity of the technique has been omitted for now.
I thus hope you can better appreciate programmers, engineers and computer scientists as artists who express their ideas and creativity by way of writing code. I’d like to have sparked the vision within you to become one yourself.
References
- https://www.geeksforgeeks.org/the-ubiquitous-binary-search-set-1/
- https://www.quora.com/What-are-some-clever-applications-of-binary-search/answer/Cosmin-Negruseri?srid=2XBD
- http://www.mathcs.emory.edu/~cheung/Courses/170/Syllabus/07/bisection.html
- https://en.wikipedia.org/wiki/Binary_search_algorithm#Variations